
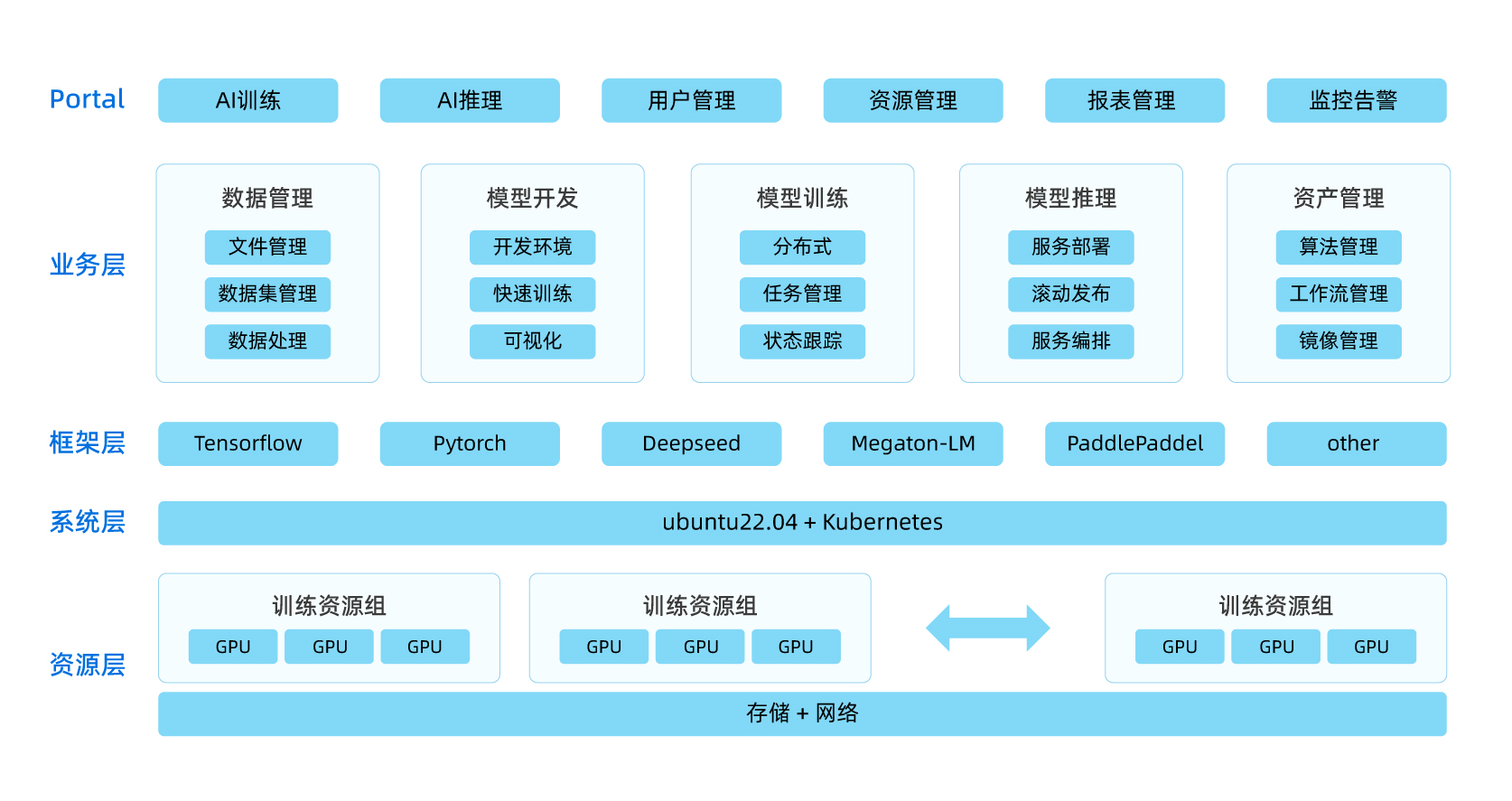
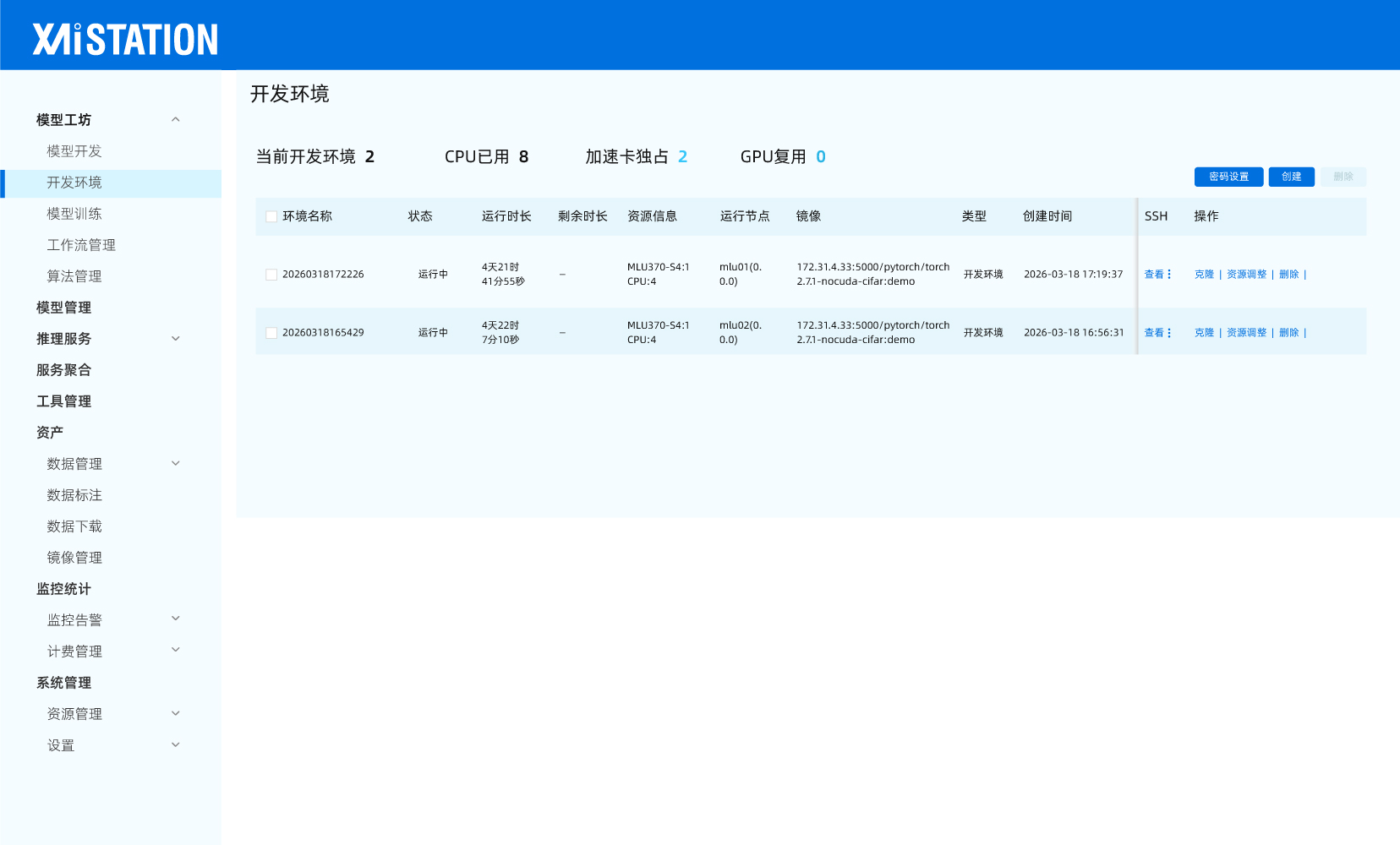
| 平台优势 | ||
异构算力统一纳管: 可以同时支持NVIDIA GPU、华为昇腾、寒武纪、海光DCU等算力集群纳管;提供标准CUDA/ROCm/CANN算子库适配层,降低模型迁移成本。 AI原生调度策略: 支持拓扑感知调度,显存超分、训练-推理混部和多集群联合调度和算力协同能力。 全栈性能优化: 可实现计算优化、通信优化、存储优化和网络传输优化。 MLOps全生命周期支持: 预置PyTorch/TensorFlow/PaddlePaddle等框架镜像,提供模型训练和和推理的精细化管理,提供实验管理的精细化控制,提升客户对算力资源的使用效率。 | 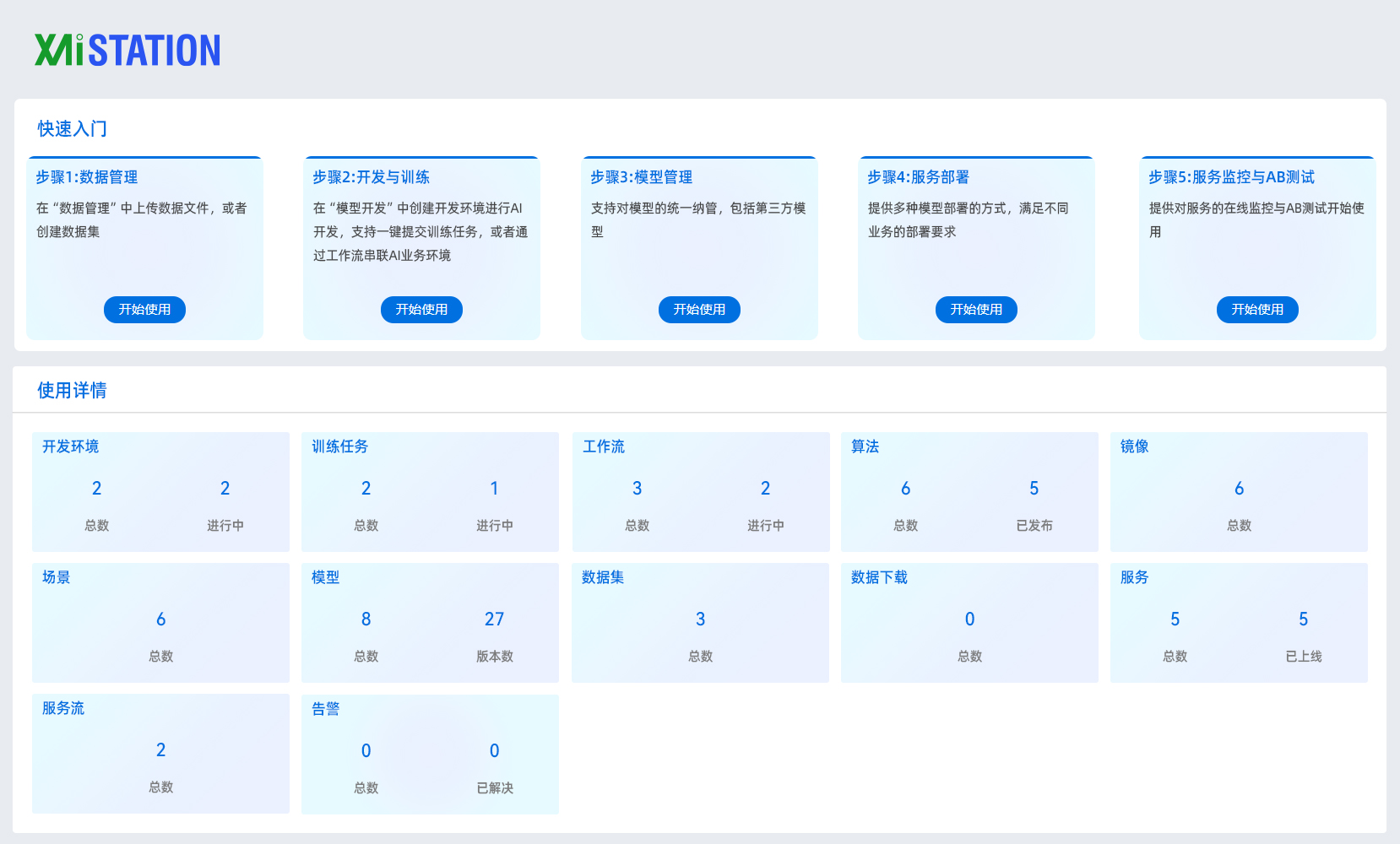 |
| 适用场景 | ||
大模型训练厂家: 大模型研发企业、科研院所,将千卡集群线性加速比从60%提升至90%,训练周期缩短30%; 行业模型精调中心: 银行、医院、车企的AI中台部门,精调任务资源成本降低50%,模型上线周期从天级缩短至小时级; 智能算力云服务: 智算中心运营商、云服务商,资源利用率提升至60%+,支持包年包月/按需/竞价多种商业模式; AI for Science科研平台: 国家超算中心、高校超算平台、药企研发部门,统一平台替代分散的HPC与AI系统,运维成本降低40% 边缘智能协同: 车企数据中心、工业互联网平台、智慧城市运营商,数据不出域的隐私计算,边缘推理延迟<10ms | 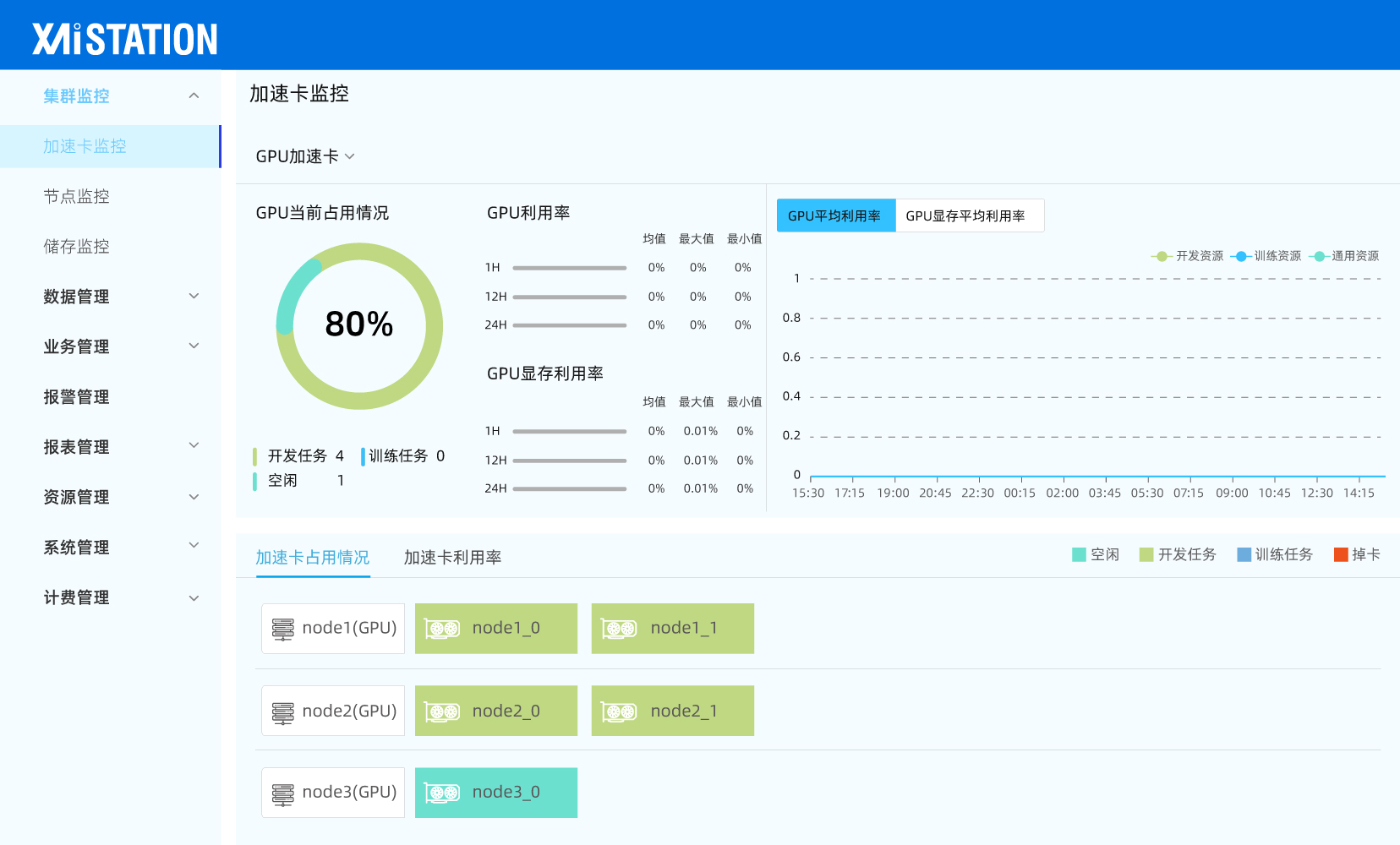 |


